Is Outbox Pattern a Bad Idea?
The outbox pattern is a popular approach for ensuring data consistency in asynchronous distributed systems. It offers tons of advantages compared to a naive approach to message sending that doesn’t guarantee consistency between a broker and a data service. In recent years, my team considered it a must-have for every system that publishes messages. That was a mistake on my part.
I’d like to share my thoughts about the outbox pattern and its disadvantages when compared to some change-capturing mechanisms. This is under the assumption that the system should be consistent and possess a database that maintains an entity, changes to which should be published to a message broker.
Database Volume Overhead
It’s evident that the outbox pattern requires an additional table in the database. This might be necessary if events are domain instances marking transitions between statuses. However, for state transfer events, we essentially duplicate the data from the main entity into another table.
The outbox quickly becomes the largest table in the entire system, multiplying the data volume several times over.
Of course, we can clean it up periodically, but many systems lack this functionality or intentionally retain the data as an audit log or for retry functionality.
Publishing Multithreading & Batching
Usually, the outbox has a single worker who publishes events to the broker. The simplest approach selects a batch or even a single record from the outbox and publishes it using a blocking operation.
Why is so inefficient? Because trying to unblock the publisher could lead to order violations. Generally, we could tweak these processes by extracting smaller parts of the processing to different threads or by grouping them by partition attributes. However, some form of locking will always be necessary to keep the single-threaded publishing process intact.
With change capturing, we generally expect that order is preserved only for events related to a single entity. As a result, the entire process can be parallelized since we are operating on the entity’s last state.
Transactions
This is particularly relevant if your system receives user requests, and you need to ensure a short response time. The outbox inherently results in larger transactions. Of course, if you don’t experience high loads and users modify one entity at a time, it won’t be problematic. But what if you have demanding requirements?
With certain NoSQL solutions, transactions might not be necessary. Let’s say you’re using MongoDB and users usually modify only one record. A transaction isn’t needed. For bulk processing, you’d only need to enable a transaction on a single collection. But with the outbox, multi-collection transactions are always necessary.
It’s a direct consequence of the database overhead. Transactions need to operate on multiple collections, writing twice as much data as required.
And once again, bulk processing becomes problematic. If you wish to process multi-record requests in multiple threads, you’ll likely encounter a bottleneck. In short, the outbox demands transactions, necessitating a single DB connection for the entire request, which then means all records have to be written to the database in a single thread.
Having worked with Java and Spring, I see that the standard approach ensures that all tasks are handled in a single thread. We could design mechanisms to offload some processing parts to other threads, but that requires extra effort.
Complex Data Models
This section might be specific to my approach to entity isolation. Personally, I use the DDD approach to isolate modules. Each module operates on a segment of the data tree called an aggregate. Ideally, each module should push its events to the outbox.
However, systems integrated with ours aren’t concerned with our aggregates. I’m sure they’d be frustrated if we required them to understand and apply our module separation on their side.
Disclaimer: I’m aware that the typical suggestion from the DDD community is to redesign the entire system because it is highly likely that the aggregates aren’t set up correctly. But let’s be real – many systems aren’t designed perfectly, and complete redesign is not an option.
My task often involves delivering a singular change event that encapsulates changes from different aggregates. With the outbox, I need to pull all of these into a transaction and then dispatch a single event, breaking isolation.
Let’s assume we have a representation level that combines several aggregates for client systems. Once out of the transaction, we could call upon this layer to receive the data set to be dispatched. This approach seems more favorable as it separates our domain operations from data representation.
Scope of Change
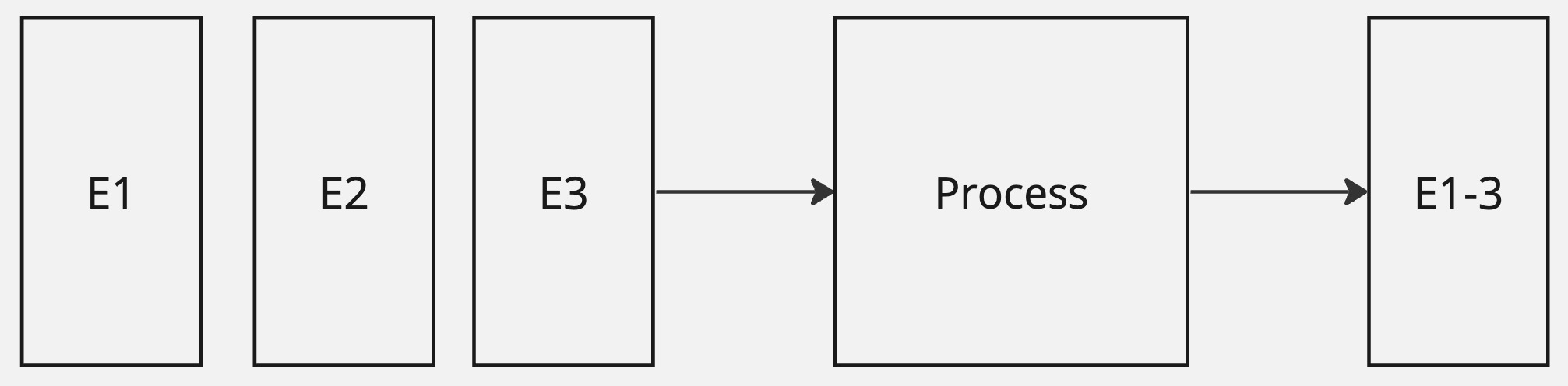
When working with the outbox, we’re usually tethered to transactions. Consider a scenario where we sequentially modify a single entity. The consumer would ideally like to receive a single event reflecting the final state. Within the scope of a transaction, it’s challenging to foresee whether more changes will occur soon.
Change capturing can be more flexible. We can define event publishing to occur after periods of inactivity, capturing only the last change.
Consider another situation where an entity can be modified from various sources at once. For example, let’s examine parallel changes from some event system and a user request. We might want to send a combined event that reflects both changes.
If both the event and request are separate transactions, change capturing can merge them, while the outbox would usually send separate notifications. While the outbox can be tweaked to introduce delays before dispatching and choosing only the last event for each entity (or composition of entities), it seems to be counter-intuitive to the principle of the outbox.
Handling Existing Data
One significant advantage of change capture over the outbox pattern concerns dealing with existing data. If you have a cursor that defines where to start scan for changes, it will be enough to set it to the oldest change in the system.
The outbox pattern generally requires creating migration scripts if there’s a need to publish events for pre-existing data. This is because in the outbox pattern events are created during transactions, so if the transaction didn’t create the event, you need the new one. Which will most probably be executed in the migration script.
Data Curation & Migrations
When support teams need to make changes to the application’s data, those changes should be sent as events. With the outbox pattern, you’re tied to predefined endpoints. Although limiting data access can be good for security and data consistency, it might hinder operational efficiency. Sometimes, directly editing the database might be more pragmatical, so that decision should be consulted with business stakeholders.
Another scenario where direct changes to the database might be needed is during data migrations. Data should evolve with the application, but every change should be accompanied by an event. This can increase the preparatory work for each migration, making the process more time-consuming.
Conclusion
In summary, the outbox is a good approach, especially when transferring domain events. However, for state transfers, it might not be the ideal choice.
Before implementing the outbox, ask yourself:
- Is the response time for user requests crucial or problematic in your system?
- Do you need to ensure quick event delivery?
- Is there a need to consolidate multiple changes into a single event?
- Do your events need to combine multiple aggregates simultaneously?
- Do you need to handle data that is already stored in the database?
- Do you need to apply data curations and migration to your data?
The last thing, change capturing has its own set of limitations that were out of the scope of the current post. I would suggest considering them before making a choice.