Event sending

Over the past seven years, the majority of my projects have involved a component that communicates with other applications through events. Each time, we were faced with the decision of how to design the event publishing mechanism.
This note aims to examine various event publishing approaches and outline the fundamental factors that should be considered when selecting the most suitable option for your project.
First, let’s establish a working definition of the term event as it applies to the context of this post. An event can be understood as a message transmitted to another system to inform it about changes or trigger some reaction. A source system generates events as a consequence of specific actions performed within it, which could be initiated by a user or through automated processing, often altering the state of the data.
An essential assumption is that the source system stores its state in some database, and events are closely associated with data modifications stored within the system. Furthermore, the events we are considering are published to an external message broker, rather than an internal event bus. This distinction is significant because it introduces the requirement to maintain consistency between event messages and the state of the data within the source system.
For this reason, I leave out-of-scope event-sourcing systems as they don’t have a conflict between the primary data store and the message broker.
To provide a clearer understanding of events in this context, let’s enumerate some key characteristics:
- Unique identifier: Each event should be identifiable; it may help to track processing and deduplicate events.
- Timestamp: Events have a timestamp that indicates when they were generated and allow the system to keep their order.
- Source entity reference: Commonly, each event is related to some entity stored in a database, events grouped by that reference and sorted by timestamp represent the history of that entity.
- Payload: We expect that the event carries some data associated with the change or action it represents.
One critical aspect to consider is the order of events. Maintaining the correct order of events is essential because it ensures that the recipient systems process the changes in the correct sequence, preventing inconsistencies and incorrect processing of the events. In many cases, the order of events directly impacts the correctness and consistency of the overall system state.
However, the order of events can be maintained within a specific scope rather than globally. The system’s requirements determine the scope of the order, and it can vary depending on the application’s needs.
In systems that use Domain-Driven Design (DDD), a common choice for maintaining event order is to focus on a particular aggregate, ensuring that events related to that aggregate are processed in the correct order.
Maintaining global order across multiple entities or systems can be challenging and require additional mechanisms or coordination between systems. One of the drawbacks of enforcing global order is that it would necessitate processing all events in a single thread, effectively preventing parallelism in event processing. This constraint can lead to performance bottlenecks and limit the overall scalability of the system.
Delivery Semantics
For event-driven systems is important to understand how events are delivered to the recipients. So let’s briefly discuss the different delivery semantics that impact how events are transmitted and processed between systems. Delivery semantics refer to the guarantees provided by the message broker concerning the successful delivery of events to their intended recipients.
There are three primary delivery semantics:
- At-most-once: In this approach, the system makes only one attempt to deliver the event. Events couldn’t be duplicated, but any failure will cause data loss.
- At-least-once: In this approach, the system retries delivery when it fails. So data shouldn’t be lost but eventually, the event could be delivered more than once.
- Exactly-once: A more theoretical option that assumes that we can control all border cases and deliver events exactly once. Unfortunately, it is mostly impossible in systems that operate on many data stores and message brokers. However, we could create our system to tolerate duplicates and ignore them, using practices such as idempotence and deduplication on the recipient side.
Our primary focus will be on the At-least-once delivery semantic. It is generally assumed that events are important to our system, and losing them is not acceptable. Achieving Exactly-once delivery is often unrealistic when using a separate database to store events and a distinct broker for event publication.
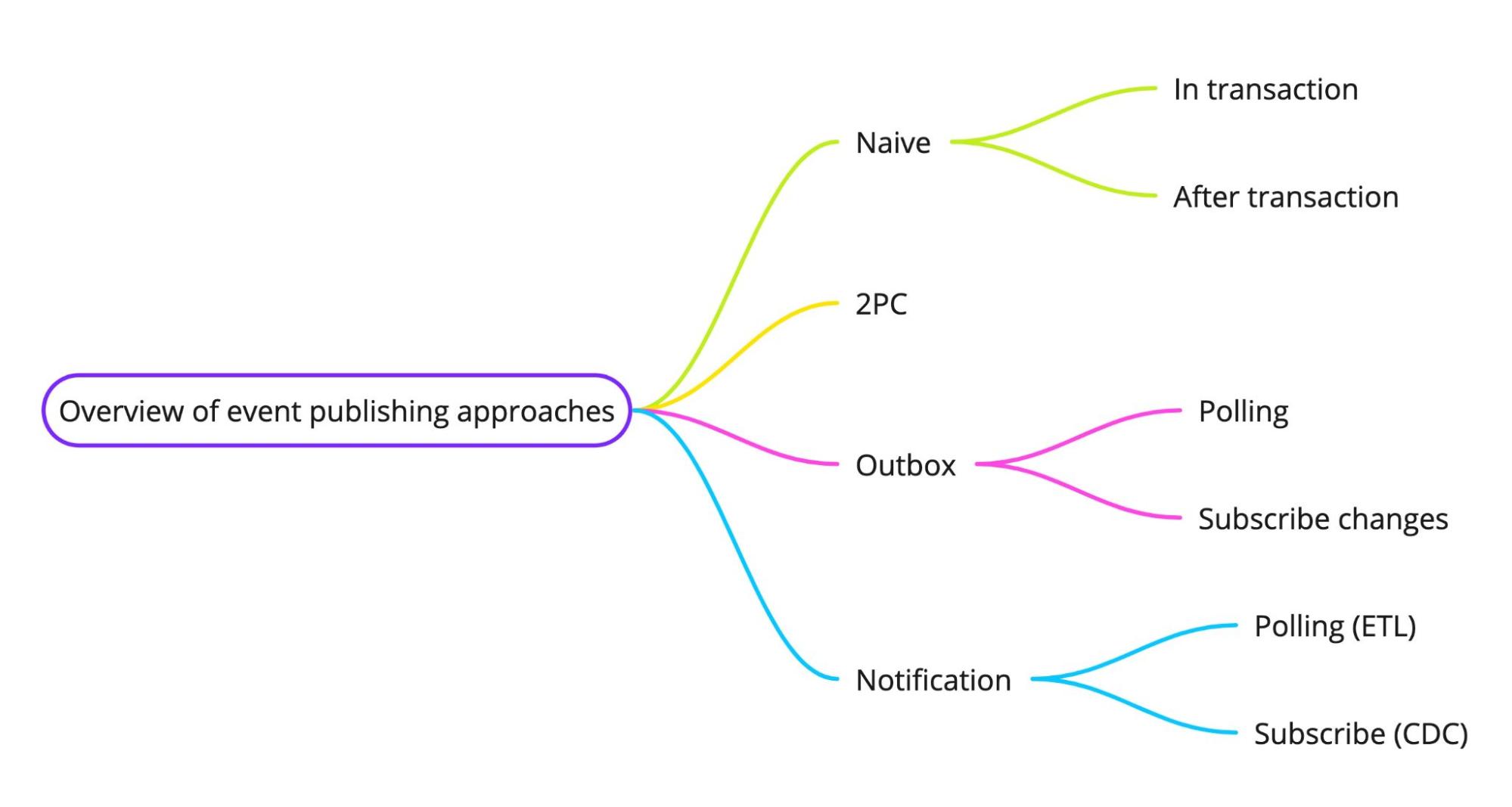
Naive Implementation
There are two fundamental approaches to event publishing in a simplistic implementation. Both methods have inherent disadvantages that can result in inconsistencies and pose risks to event-driven systems.
Nevertheless, these strategies are more straightforward to deploy and may be viewed as potential solutions to reduce complexity. In the end, whether or not a solution is acceptable for a specific case depends on its ability to meet the requirements.
Publish the event before the transaction is committed.
In this approach, the event is published before the end of the transaction end, and the transaction fails when we can’t send an event to the broker.
Suppose the transaction fails to commit after the event is published. In that case, the recipient system might have already processed the event and updated its state based on the event data, leading to inconsistencies between the source and recipient systems.
On the other hand, if sending is failed, we will be able to roll back the transaction. So we could use that approach when inconsistency is acceptable and sending the event is more important than saving the state in the source system.
Usually, the source system is used as a reference for the correct state, commonly named the source of truth. We may potentially treat the broker as the source of truth because it will keep a complete state, but it will require a broker that allows keeping messages after delivery (for example, Kafka).
Publish the event after the transaction has been committed.
In this alternative approach, the event is published after the transaction that modifies the source system’s data has been successfully committed. This method presents its own challenges:
If the event publication fails after the transaction commit, the recipient system will not be aware of the changes made in the source system, resulting in data inconsistencies. So we could use that approach when inconsistency is acceptable and saving the state in the source system is more important than sending the event.
It seems to be a good solution for cases when events are used for some non-strict calculations like approximate statistics. Or if the system can detect inconsistency across systems and automatically retrigger event publishing.
For this implementation, we could say that it satisfies the at-most-once semantic.
Two-Phase Commit (2PC)
Two-Phase Commit (2PC) is a distributed transaction protocol that can be used to ensure data consistency and reliable event publishing in non-event sourcing systems. In our case, it could establish transactions shared between the broker and the data store.
So changes on an entity will be committed only if the event were published to the broker and vice versa. We couldn’t say that it is exactly once delivery because we don’t cover the consumer side, but it allows us to implement the at-least-once semantic.
How 2PC works
Prepare phase: The transaction coordinator requests all involved resources (database and message broker) to prepare for the transaction commit. Each resource locks the necessary data and verifies whether the transaction can be successfully committed. The resources then respond with either an agreement or disagreement.
Commit or abort phase: If all resources agree to commit, the transaction coordinator instructs them to proceed with the commit. If any resource votes to abort, the coordinator orders all resources to roll back the transaction.
Pros of 2PC
- Ensures data consistency and atomicity across multiple resources, preventing the issues associated with naive implementations.
- Works well in scenarios where strong consistency is required between the source system’s data and the published events.
Cons of 2PC
- Not supported by all message brokers.
- Performance overhead: The two-phase commit process introduces additional latency and increases the complexity of the transactions, as it requires coordination and communication between all involved resources.
- Scalability Issues: 2PC can create bottlenecks and contention due to the need for locking resources during the preparation phase, potentially impacting the system’s overall throughput and responsiveness.
- This may cause some broken state of data: If the transaction coordinator fails during the 2PC process, the involved resources may be left in an uncertain state, causing potential deadlocks or inconsistencies.
Outbox Pattern
The Outbox Pattern is an alternative approach to ensuring data consistency and reliable event publishing in non-event sourcing systems. It provides a mechanism to decouple transactional data modifications and event publishing while maintaining the necessary consistency guarantees and the at-least-once semantic.
This pattern is beneficial when the message broker does not support 2PC or its performance and scalability trade-offs are undesirable.
How the Outbox Pattern works
Rather than directly sending events to the message broker, the source system saves the events in an “outbox” table within its database. That is done as part of the same transaction that alters the data, ensuring that the outbox always remains consistent with the entity.
The broker will only receive these events when another component transfers them from the outbox to the broker. This process can be delayed if the broker is temporarily unavailable or retried multiple times, allowing greater flexibility and consistency in event handling.
Pros of the Outbox Pattern
- Data consistency: By storing the data modifications and event generation within the same transaction, the Outbox Pattern ensures consistency between the source system’s data and the published events.
- Decoupling: The pattern separates the concerns of data modification and event publishing, allowing each to be optimized independently and reducing the complexity of the transactional code in the source system.
- Scalability: The Outbox Pattern avoids the resource locking and contention issues associated with 2PC, enabling better performance and scalability.
Cons of the Outbox Pattern
- Overhead on the database: At least all events should be stored in the database, which increases the number of operations performed on it. This approach may also necessitate extra tasks during event publishing, such as marking events as sent or querying the database for new pending events.
- Increase delivery time lag: Since the event publishing is performed asynchronously in another process, it will cause additional delay for each event.
- Additional complexity: Implementing the Outbox Pattern requires managing the outbox table and the event publisher and handling potential failures, adding complexity to the overall system design.
Outbox: Data Polling
Let’s assume that events have already been saved in the database and now need to be published to the broker. Data polling involves a scheduled task periodically checking the database for new events stored in the outbox.
A significant challenge in outbox implementation based on polling is ensuring that only unpublished events are selected for publication. It could be done in two general ways:
- Using the ‘sent’ flag: that approach assumes that the outbox records have some field that marks that particular record is not sent. That implementation increases overhead on the database because it requires performing a written request to update the state of that flag after event publishing. However, on the other hand, this approach tends to have fewer edge cases that need to be addressed.
- Using cursor: This method assumes that the polling component maintains a timestamp or a sequential identifier value of the most recently published event. This allows for the selection of outbox records added after that point. We can refer to this value as a cursor since it determines the starting point from which we look up new records. However, correctly implementing this method can be challenging. It’s important to consider that identifiers and timestamps might become visible in a different order than they were generated due to transaction isolation. Therefore, it’s necessary to employ a time window to look back at a certain point before the cursor and later deduplicate those records. Another issue that may arise is the insufficient precision of timestamps. If the same timestamp is used as a cursor and is shared by more records than the desired lookup query size, the publishing process may get stuck.
Pros of Data Polling-Based Outbox
- Database compatibility: Data polling can be implemented with virtually any database, making it a versatile solution that can be adapted to a wide range of existing systems.
- Customization: Developers have the freedom to create their custom data polling solution tailored to their specific requirements and system constraints without relying on third-party tools or libraries.
- Reduced dependency on the database: Data polling relies less on specific database features or versions, simplifying maintenance and making it easier to switch or upgrade databases without significantly affecting outbox implementation.
Cons of Data Polling-Based Outbox
- Polling overhead: Data polling introduces additional load on the database, as the polling component continually queries for new events. This overhead can become significant in high-throughput systems.
- Potential inconsistency: Ensuring consistency between the source system and the message broker can be challenging, especially in cursor-based polling, where transaction isolation may cause identifiers and timestamps to become visible in a different order than they were generated.
- Latency: As events are published periodically, there may be a delay between when an event is saved in the outbox and when it is actually published to the message broker. This latency can be a concern in systems that require near-real-time event processing.
- Deduplication and time window management: Implementing deduplication and time window management can add complexity to the system, particularly in cursor-based polling, where edge cases and precision issues may arise.
Outbox: Subscription
An alternative approach to implementing the outbox pattern is using a subscription mechanism provided by the database or through additional tools. In this method, instead of polling the database periodically for new events, the application subscribes to changes in the outbox table and reacts to them as they occur. That allows for real-time event publishing and reduces latency compared to data polling.
To implement the subscription-based outbox, you must choose a database that supports subscribing to changes in the data, either as a built-in feature or by using third-party tools like Debezium. Some databases offer subscription features as part of their core functionality, while others may require additional tools or paid services, such as Oracle GoldenGate.
How the Subscription-Based Outbox works:
In a subscription-based outbox implementation, the database manages the cursor that determines from which point new events should be read. That greatly simplifies the process, as the application only needs to focus on processing the changes received from the database. Additionally, since the database takes care of notifying the application about changes, this approach eliminates the need to mark entries as sent, reducing the overhead on the database.
Pros of the Subscription-Based Outbox:
- Real-time event publishing: Subscription-based outbox implementations enable near-real-time event publishing, reducing latency compared to polling-based solutions.
- Minimal impact on the source system DB: Since the Subscription-based outbox receives change notifications from DB, it does not introduce additional load by requests. Also, it doesn’t need to mark entries as sent because the database or tool manages the cursor from which changes should be read.
- It has no border cases related to the lookup of unsent events, as it is managed by a database or tool.
Cons of the Subscription-Based Outbox:
- Applicability: requires a database that supports the subscription mechanism.
- Database-specific features and limitations: Implementing a subscription-based outbox may require utilizing database-specific features or third-party tools, which can increase complexity and lock you into a specific database solution. Each tool or database mechanism may come with its own restrictions that must be considered.
- Potential challenges in event ordering: Ensuring correct event ordering may require additional mechanisms or coordination, depending on the subscription features provided by the database or tool. When the subscription is based on a transactional log that could be purged, you may lose an order or even fail to process when trying to read the already removed part of the log.
- Less control with tools: When using third-party tools or database mechanisms for managing subscriptions, you might have limited control over the implementation, making it difficult to customize or modify the solution to meet specific requirements.
- Paid or hard-to-maintain tools: Some subscription-based tools or database features may require paid licenses or subscriptions, increasing the overall cost of the solution. Additionally, maintaining these tools could be challenging, especially if you don’t have access to the necessary support or resources.
Change Notification as an Alternative to Outbox
Outbox assumes that processes in the application produce not only data changes but explicitly define events. Seems that is a good way to populate some event that contains the intention of the data changes, but many systems operate on events that only contains changes in the data. For those cases, we could extract logic that publishes events to a separate component that will watch for changes in the data and publish events independently from the main processes.
Generally, that process could be called ETL (Extract-Transform-Load). A dedicated ETL component could scan data for the changes to extract modified entities, transform them to some event format, and load them to the broker. Commonly that process will be based on Data Polling, and implementation will be mostly similar to Data Polling-Based outbox implementation.
Alternatively, the system could use some change subscription mechanism and allow the process of changes closely to real-time. That approach is also called Change Data Capture (CDC).
How Change Notification Works:
In the Change Notification approach, events are generated based on data changes detected either through data scanning or database triggers. When a data change is detected, the system generates an event and publishes it to the message broker. Unlike the Outbox pattern, events are not explicitly created as part of the transaction; instead, they are derived from the data modifications themselves. This process can be automated using ETL or CDC tools, which monitor the source database for changes and generate corresponding events.
- Transaction processed and committed
- In the case of polling, it should update a timestamp field that stores the date of the last change.
- Receive notifications from DB or polling to detect new changes
- The notification component retrieves all required data from the database
- Data transformed to target format (event schema)
- The event was published to the broker
Pros of the Notification Approach:
- Decoupling: Change Notification decouples the main transaction code from event generation, potentially improving the performance of the source system.
- Flexible processing: For example, it allows merging consecutive changes when only the final state of an entity is important, resulting in a more efficient process.
- Enrich data: That approach allows adding data that doesn’t relate to the transaction or even from other data sources. Generally, the outbox is also able to enrich events with data not strictly related to the transaction, but it could be challenging as it may affect transaction duration or has problems with visibility (you should remember that you will be in the scope of your transaction, and if you add some entities not related to it they could be modified in the same time, that will cause that booth concurrent transactions will not be able to build fully correct state of date, just because they will not have access to the other transaction state).
- Independent Change Detection: The notification mechanism is agnostic to the cause of data changes. Suppose your application has support staff who may need to modify data directly in the database. In that case, the notification system can still capture these changes, regardless of whether the system initiates them or not.
Cons of the Notification Approach:
- The lost intention of that data change: This solution cannot be applied in cases when an event represents some intention of the data change
- As notifications are less coupled with transactions, it could be harder to troubleshoot and test how they apply to the scope of the transaction.
Notification: Data Polling
Change notification can be implemented using data polling; this approach is conceptually similar to the polling-based outbox, with several differences:
- it scans the tables or collections containing the changed entities directly, rather than an outbox table.
- on outbox we are interested in new records; for the notifier, we should also process update and remove operations.
Also, this solution has some challenges, especially when using an implementation based on cursors, as it may require introducing work with time windows to handle the problem with visibility caused by transaction isolation.
However, this method can be particularly useful when database-level triggers or other built-in CDC mechanisms are not available or feasible.
How the Data Polling-Based Notifications works:
- The data polling method periodically checks the database for new entity changes. It could be done using several approaches:
- Time cursor-based: For that approach entity should store the time of the last modification, and the polling component should store the timestamp of the last sent notification; we will call it a cursor. Generally, it used to periodically request DB for entities that were sent later than the cursor. But we should also consider that change timestamps may become visible in another order than they were created. To handle that polling component, probably will use a back window and some deduplication mechanism.
- Flag based: For that approach, we should store flags that mark the entity as already processed. It is a little bit closer to the outbox because that approach requires updating that flag each time when a transaction changes any data in it. Please note that storing that flag in the target entity could cause write conflicts between the notification sender and the main logic.
When changes are detected, the polling component should enrich data, transform it to the required notification format, and send it to the broker.
At the end of the polling iteration, it should mark entities as processed by updating flag value or saving the current cursor value.
Pros of the Data Polling-Based Notifications:
- No need for a separate outbox table, simplifying the database schema and reducing data duplication.
- Can detect changes made outside of the system, such as manual modifications by support staff.
- Database-agnostic: This approach can be implemented independently of the specific database system or built-in CDC mechanisms, providing a more flexible and adaptable solution.
- Decoupling: The approach decouples data modification from event generation and processing, allowing the source and recipient systems to evolve independently.
- Customization: The polling component can be tailored to generate events based on specific requirements or domain models, providing event schema design and processing flexibility.
Cons of the Data Polling-Based Notifications:
- Polling overhead: Periodically polling the source system’s database can introduce latency and increase the load on the database, potentially impacting its performance.
- Eventual consistency: Since the scraper polls the database at intervals, the recipient systems may not receive updates in real time, leading to temporary inconsistencies between the source and recipient systems.
- Require to manage sent flags or cursors, which usually requires a separate table or collection.
- Requires the implementation of time windows and deduplication mechanisms to apply correct polling.
Notification: Subscription
A subscription-based approach is another method for implementing change notifications, commonly called Change Data Capture (CDC). That approach uses a database native change subscription mechanism or some tool that can detect database changes in real-time (for example, Debezium uses a transactional log of the database to catch changes).
How the Subscriptin-Based Notifications works:
In the subscription-based method, the system subscribes to the database’s change notifications or uses a CDC tool like Debezium to receive real-time updates. As changes are made to the database, the subscribed system or tool receives messages about these changes, typically on a per-table or per-collection basis.
To process the received changes, the system may need to merge them using a streaming mechanism like Apache Flink or Kafka Streams or make additional calls to the database to retrieve related entities. This merging process helps to create a cohesive view of the changes and prepares them for further processing or forwarding.
The database or CDC tool usually manages the state of processed changes, ensuring that only new changes are sent to the subscriber. This eliminates the need for maintaining a separate cursor or flag for sent changes, simplifying the overall implementation.
Pros of the Subscription-based Notifications:
- Real-time updates: Subscribers receive notifications when changes are made, providing faster and more up-to-date information.
- Reduced database load: No need for frequent polling, resulting in less strain on the database.
- Scalable: Can handle large amounts of changes more efficiently than polling-based methods.
- Cons of the Subscription-based Notifications:
- Vendor or tool limitations: Some databases may have limited support for change subscriptions or may require paid features, while external tools may impose additional restrictions or have compatibility issues.
- Less control: Developers may have less control over the change detection process when using external tools, making customizations or modifications more challenging.
- Added complexity: The overall system complexity may increase when changes are received in parts and require processing through streaming mechanisms or additional components for data enrichment. Managing data flows and handling possible states between these components can become challenging, making the system more difficult to maintain and troubleshoot.
Conclusion
In conclusion, the choice of approach to maintain data consistency and reliable event dispatch in non-event sourcing systems is an important decision that can significantly impact the efficiency and maintainability of an application. Before making a choice, it is crucial to understand the application’s use cases, requirements, and constraints, as each approach has advantages and limitations.
Outbox vs. Notification
Outbox may be the only acceptable solution in specific scenarios. For instance, in systems where the explicit intention behind data changes must be captured, such as when a user performs a particular action that triggers a series of events, the Outbox pattern ensures that the events are generated and saved as part of the transaction. This approach provides good consistency guarantees and simplifies error handling and recovery.
On the other hand, Change Notifications might be the only acceptable solution in cases where data changes are not explicitly tied to specific user actions or when capturing changes made directly to the database by support staff is required. This approach decouples event generation from the primary transaction, allowing for more flexible processing, enriching data from other sources, event deduplication based on content, and independent change detection.
Subscription vs. Polling
When choosing between Subscription-based and Polling-based Change Notifications, several factors should be considered. Subscription-based Notifications offer real-time updates and reduced database load, making them suitable for systems requiring immediate change propagation. However, they may be limited by database vendor support or external tool compatibility and introduce added complexity to the system.
Polling-based Notifications are more database-agnostic and customizable, providing a flexible solution for applications with varying event schema requirements. However, they introduce polling overhead and additional complexity for managing flags or cursors.
In summary, the choice between Outbox and Change Notifications, as well as between Subscription-based and Polling-based Notifications, should be carefully weighed against the specific needs and constraints of the application. By doing so, developers can ensure a reliable, efficient, and maintainable solution for data consistency and event dispatch in non-event sourcing systems.